
技术 | WebRTC 音频抗弱网技术(下)
上周,我们针对音频弱网对抗技术中的前向纠错技术、后向纠错技术及 OPUS 编解码抗弱网特性进行了分享。文本分享 WebRTC 使用的抗抖动模块 NetEQ。
抖动的定义和消除原理
抖动是指由于网络原因,到达接收端的数据在不同时间段,表现出的不均衡;或者说接收端接收数据包的时间间隔有大有小。
WebRTC 通过包到达时间间隔的变化来评估抖动,公式如下:
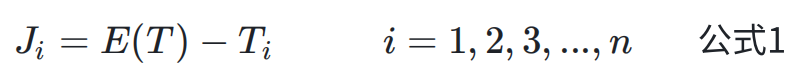
Ji定义为时刻 i 时测量的抖动,E(T) 表示包到达时间的间隔均值,Ti 表示时刻 i 收到的包距上一次收包的时间间隔。
Ji> 0 说明数据包提前到了,这样抖动缓存区数据将会出现堆积,容易造成缓冲区数据溢出,导致端到端时间延迟增大;Ji< 0 说明数据包晚到或丢失,会增大延时;不管早到还是晚到,都可能造成丢包,增加时延。
NetEQ 通过测量包达到时间间隔,来预测包在网络中的传输时间延时;根据收到的包但还未播放的缓冲语音数据的大小来评估抖动的大小。
原则上通过对网络延时的测量,以其最大延时来设置抖动缓冲区的大小,然后使每个包在网络中的延时加上该包在抖动缓冲区的延时之和保持相等,这样可以消除抖动,就可以控制语音包从抖动缓冲区以一个相对平稳的速度播放音频数据。
下图[1]说明了抖动消除的核心思想:
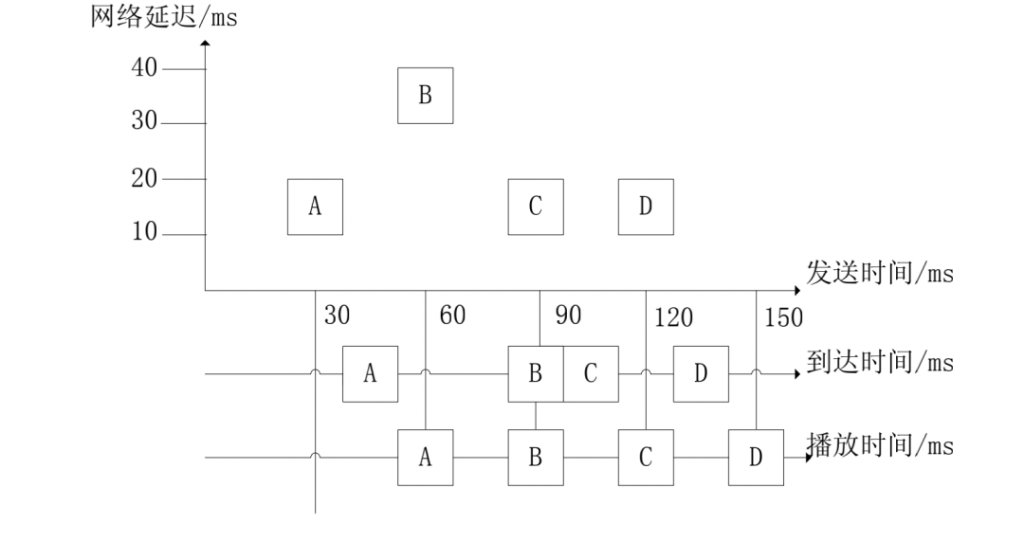
A、B、C、D 包在发送端分别以 30ms 间隔发送,即分别在 30ms、60ms、90ms、120ms 处发送;接收端接收到这些包对应的时间为 40ms、90ms、100ms、130ms;这样它们在网络中的延时分别是 10ms、30ms、10ms、10ms;包到达的间隔分别为 50ms、10ms、30ms,即抖动。
因此可以使包 A、C、D 在抖动缓存中的延时 20ms 再播放,即 A、B、C、D 的播放时间为 60ms、90ms、120ms、150ms,这样可以保持一个平稳的间隔进行播放。
NetEQ 通过估算网络传输延时,根据网络传输延时 95% 分位来调整抖动缓冲区;这使得 NetEQ 在消除抖动缓冲影响时,兼顾最小延时。
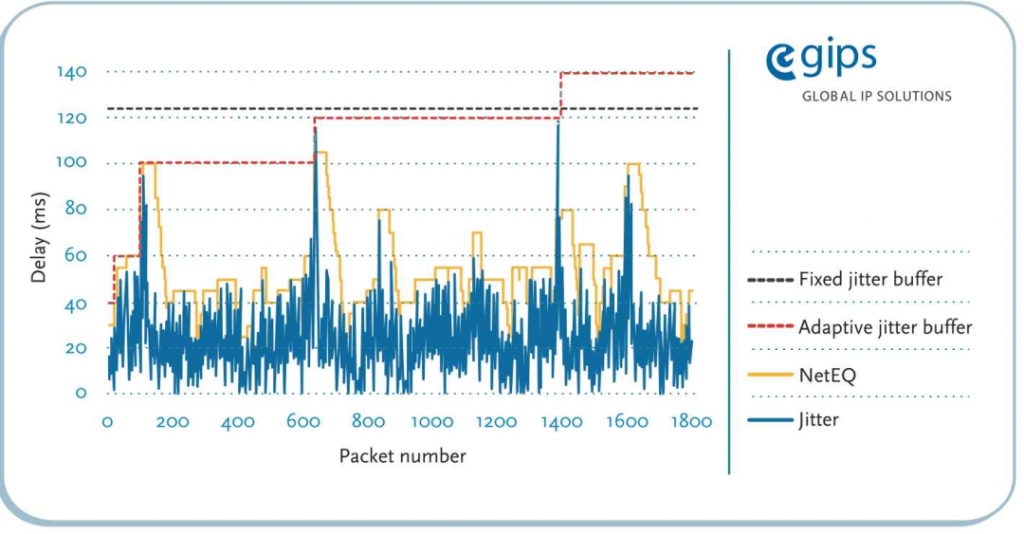
下图[2]是官方对 NetEQ 和其它技术在消除抖动带来的延时对比,可以看出 NetEQ 在消除抖动时,可以保持很低的时间延时。
NetEQ 及其相关模块
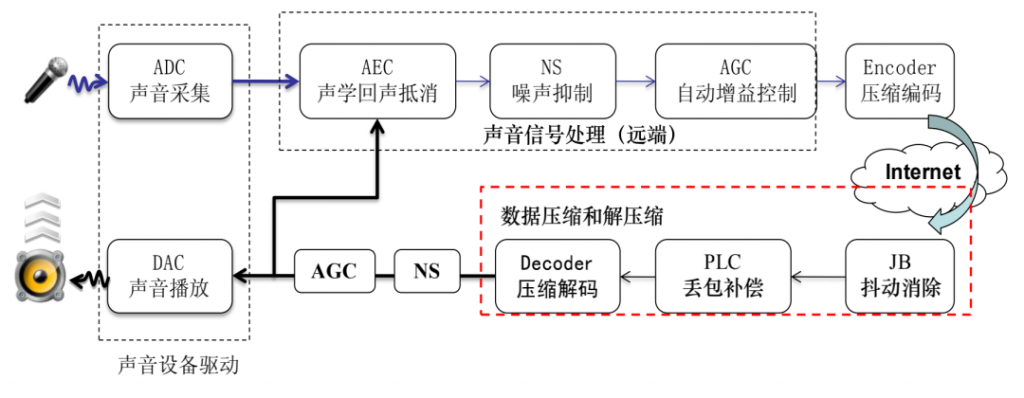
下图[1]概要描述了 WebRTC 的语音引擎架构。红色区域为 NetEQ 部分,可以看出 NetEQ 位于接收端,包含了 jitter buffer 和解码器、PLC 等相关模块。接收端从网络收到语音包后,语音包将先进入 NetEQ 模块进行抖动消除、丢包隐藏、解码等操作,最后将音频数据输出到声卡播放。
NetEQ 包含的模块见下图[1]:
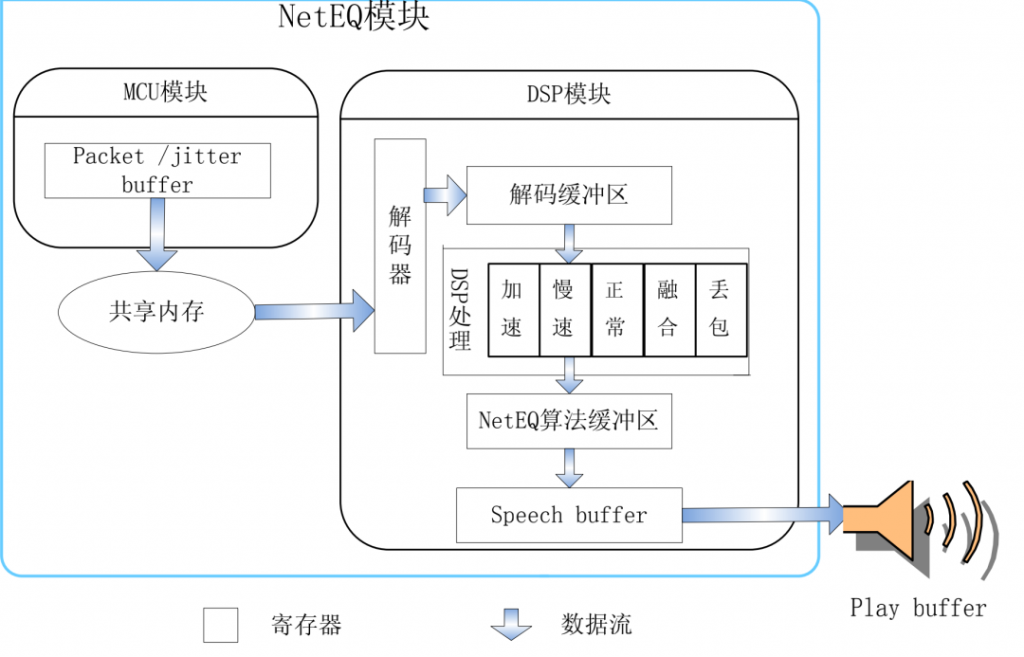
NetEQ 核心模块有 MCU 模块和DSP 模块,MCU 模块负责往 jitter buffer 缓存中插入数据和取数据,以及给 DSP 的操作;DSP 模块负责语音信息号的处理,包括解码、加速、减速、融合、PLC 等。
同时 MCU 模块从 jitter buffer 中取包受到 DSP 模块相关反馈影响。
MCU 模块包括音频包进入到 buffer,音频包从 buffer 中取出,通过语音包到达间隔评估网络传输时间延时,以及对 DSP 模块执行何种操作(加速、减速、PLC、merge)等。
DSP 模块包括解码,对解码后的语音 PCM 数据进行相关操作,评估网络抖动 level,向 play buffer 传递可播放的数据等等。
下面详细分析 MCU 和 DSP 各相关模块。
MCU
将收到的包插入 packet_buffer_
从网络收到音频包后,将其插入到抖动缓存 packet_buffer_中,最多缓存 200 个包;当缓存满了,会刷新缓存中所有的包,同时该缓存最多缓存近 5 秒的音频数据,太早的会被定时清除。
若收到的包是 red 包,会将 red 包中的每个独⽴包解析出来存入到缓存队列中,包在缓存队列中按照 timestamp 的升序进行存储,即最近的音频包存储在队列后面,老的包存储在队列前面。
收到音频包后,还会更新NackTracker 模块,该模块主要是通过包的序列号来判断是否存在丢包,若存在丢包且重传请求开启,需要向发送端发起 nack 请求,请求发送端重发丢失音频包。
估算网络传输延时
在将包插入到抖动缓存中时,根据包到达时间间隔对网络延时进行估算。这里将 WebRTC 中根据包到达时间间隔来计算网络延时,WebRTC 计算音频网络延时,主要考虑如下几点:
统计音频包到达时间间隔,取其 95% 分为作为网络时延估计。

以上公式通过计算当前包和上一个包的时间差,以及 seqnum 的差值,来计算每个 seq 包占有的时间戳范围,即 packet_per_time,然后通过当前包和上一个包收包间隔 iat_ms,来计算收包时间间隔延时,用包的个数来度量。
当正常包到达时 iat = 1,iat = 0 表示提前到了,iat = 2,表示延时一个包, 最终用包个数来衡量延迟时间。
每算出一个 iat 后,会将其插入到对应的直方图,直方图记录 0-64 个包,即记录 0-64 个包的延迟概率分布情况。所有延迟概率和为 1。
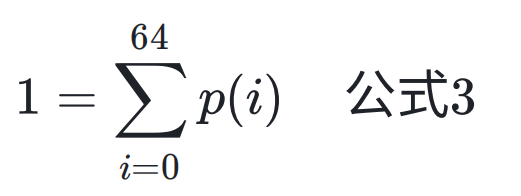
计算出当前包的到达间隔 iat,将其插入到直方图,并更新直方图每个延迟的概率,每个延迟分布乘以一个遗忘因子 f,f 小于 1, 更新过程如下:
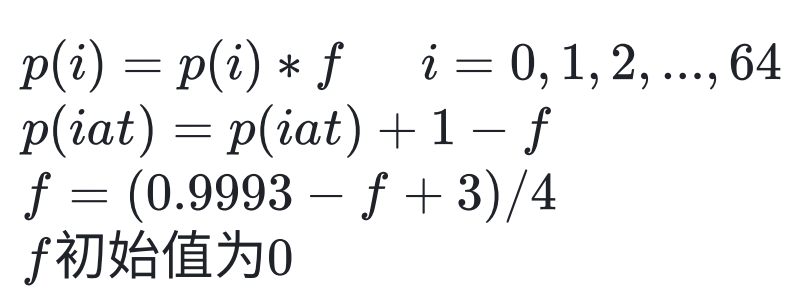
上面公式的意义是保证每次计算出一个包到达间隔延迟后,对应增加其概率,同时对其它延时分布的概率进行遗忘,使整个和保持为 1。
最后取其 95% 分为的延迟作为目标延时,即有 95% 的延迟都小于这个目标延时。
统计包到达时间间隔最大峰值
统计多个包到达间隔峰值,最多 8 个,在一定情况下,以峰值作为网络延时估计。每次计算到包到达时间间隔 iat 和按 95% 分位计算到的目标延时(记为target_level)后,来判断峰值。
认为该 iat 是⼀个延时峰值的条件是:
iat > target_level + threshold, 或 iat > 2 * target_level, 这里的 threshold 为 3
且距上次峰值时间间隔小于阈值 5s
当判断该 iat 为延时峰值时,将其添加到峰值容器中,峰值容器中每个元素记录两个值,一个是峰值 iat 值,另一个是当前峰值距离上一次峰值的时间间隔(即为 period_ms);
当峰值容器超过了两个,且当前时间距离上一次发现峰值时已流逝的时间(记为 eplase_time)小于峰值容器元素中记录的最大 period_ms 的两倍时,认为该峰值是有效的,需要从峰值容器取最大的 iat(记为 max_iat),则目标时延取值:
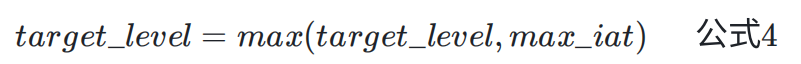
当 target_level 取值是 max_iat 时,该峰值的理论有效时间可到达 40s 以上,此处存在优化空间。
最小延时限制
根据设置最低时延,调整目标延时估计,保证目标延时估计不低于最小时延;最小时延是音视频同步计算的出来的结果。
目标延时小于该最小延时,会导致音视频不同步。
目标延时不能超过 0.75 * 最大抖动缓冲区大小
WebRTC 中默认最大抖动缓冲区为 200,所以目标延时为:
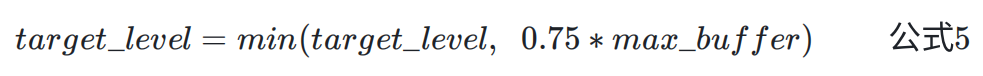
即 target_level 不大于 150 个包,也就是目标延时不大于 3s 延时。
从 packet_buffer_中取包
播放线程尝试每次获取 10ms 数据来播放,要是抖动缓冲中没有数据,则播放静音数据。
从 packet_buffer_ 中获取的数据首先需要经过解码器解码,然后再根据反馈的操作进行对应的 DSP 操作(加速、减速、丢包隐藏、PLC、融合等)。最后将 DSP 处理完的数据填入到 sync_buffer_ 中待扬声器播放,并从 sync_buffer_ 中取 10ms 音频数据进行播放。
计算抖动延时
根据抖动缓冲区 packet_buffer_ 和 sync_buffer_ 中未播放完的音频数据总延时 total_dealy,来更新计算抖动缓存延时 filtered_level

若经过加减速操作,需要从 filtered_level 中消除加减速操作后引入的延时变化,如下所示:

获取对应的操作
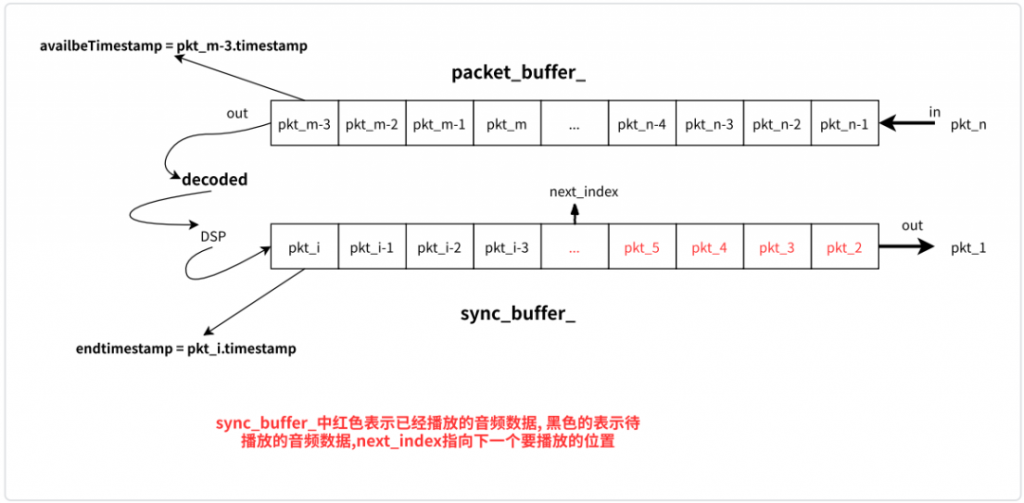
下图中的 packet_buffer_ 和 sync_buffer_ 中未播放的数据大小可以理解为抖动缓冲区大小,从图中可看出数据从 packet_buffer_ 取出后,经解码器解码、DSP 处理,最后进入 sync_buffer_中待播放。
low_limit = 3/4 *target_level high_limit = max(target_level, low_limit + window_20ms
但进行何种 DSP 操作处理呢?
NetEQ 将根据 packet_buffer_和 sync_buffer_中未播放的音频数据总延时(记为 total_delay),以及 sync_buffer_ 中最后待播放的音频数据的时间(记为 endtimestamp),和 packet_buffer_首包的时间(记为 avaibleTimestamp),以及 target_level 和 filtered_level 的关系,来综合判断接下来执行何种 DSP 操作。
下面将对几种核心的 DSP 处理操作条件进行简要说明:
norml 操作
满足以下条件之一,将执行 normal 操作
1. 若原本要做 expand 操作,但是 sync_buffer_ 待播放的数据量大于 10ms。
2. 连续 expand 操作次数超过阈值。
3.当前帧和前一帧都正常到达,且 fitlered_level 在 low_limit 和 higth_limit 之间。
4. 上一次操作是 PLC,当前帧正常,但当前帧来得太早,执行 normal 操作。
5. 当前帧和前一帧都正常到达, 原本通过 filtered_level > high_limit 判断,要加速操作,但是 sync_buffer_ 待播放的音频数据大于小于 30ms。
expand 操作条件
当前数据包丢失或者还未到达时,同时在 sync_buffer_ 待播放的音频数据小于 10ms 时,则满足下面 4 个条件中任何一个,都将执行 expand 操作。
1. packet_buffer_ 没有可获取的音频数据。
2.上一次是 expand 操作,且当前 total_delay < 0.5* target_level。
3. 上一次是 expand 操作,且当前包(即availbeTimestamp – endtimestamp 大于一定阈值)来的太早,同时当前 filtered_level 小于 target_level。
4. 上一次包非 expand(加速、减速或 normal),且 availbeTimestamp – endtimestamp >0,即中间存在丢包。
加速操作
上一个包和当前包都正常到达,filtered_level 大于 hight_limit,且 sync_buffer_ 中待播放的数据量大于 30ms。
减速操作
上一个包和当前包都正常到达,filtered_level 小于 low_limit。
merge 操作
上一次为 expand 操作,当前包正常到达。
DSP
基音[3]
基音是指发浊音时声带振动所引起的周期性对应的信号基本谐波,基音周期等于声带振动频率的倒数。一般的声音都是由发音体发出的一系列频率、振幅各不相同的振动复合而成的。
这些振动中有一个频率最低的振动,由它发出的音就是基音,其余为泛音。基音携带了大部分能量,决定了音高。
基音的周期提取,一般使用短时自相关函数,因为自相关函数一般在基于周期上表现出有极大值的特点。在 NetEQ 的 DSP 信号处理中,基音的提取是一个至关重要的步骤。
语音的拉伸[4]
对语音的拉伸变速,有时域方法和频域方法。时域方法计算量相对频域方法少,适合 VoIP 这种场景;频域方法适合频率激烈变化的场景,如音乐。
NetEQ 中对语音的拉伸(加速或减速)使用的是 WSOLA 算法,即通过波形相似叠加的方法来变速;该算法在拉伸语音时能够保证变速不变调。同时该算法是时域算法,对语音有比较好的效果,下图是其大致原理和流程:
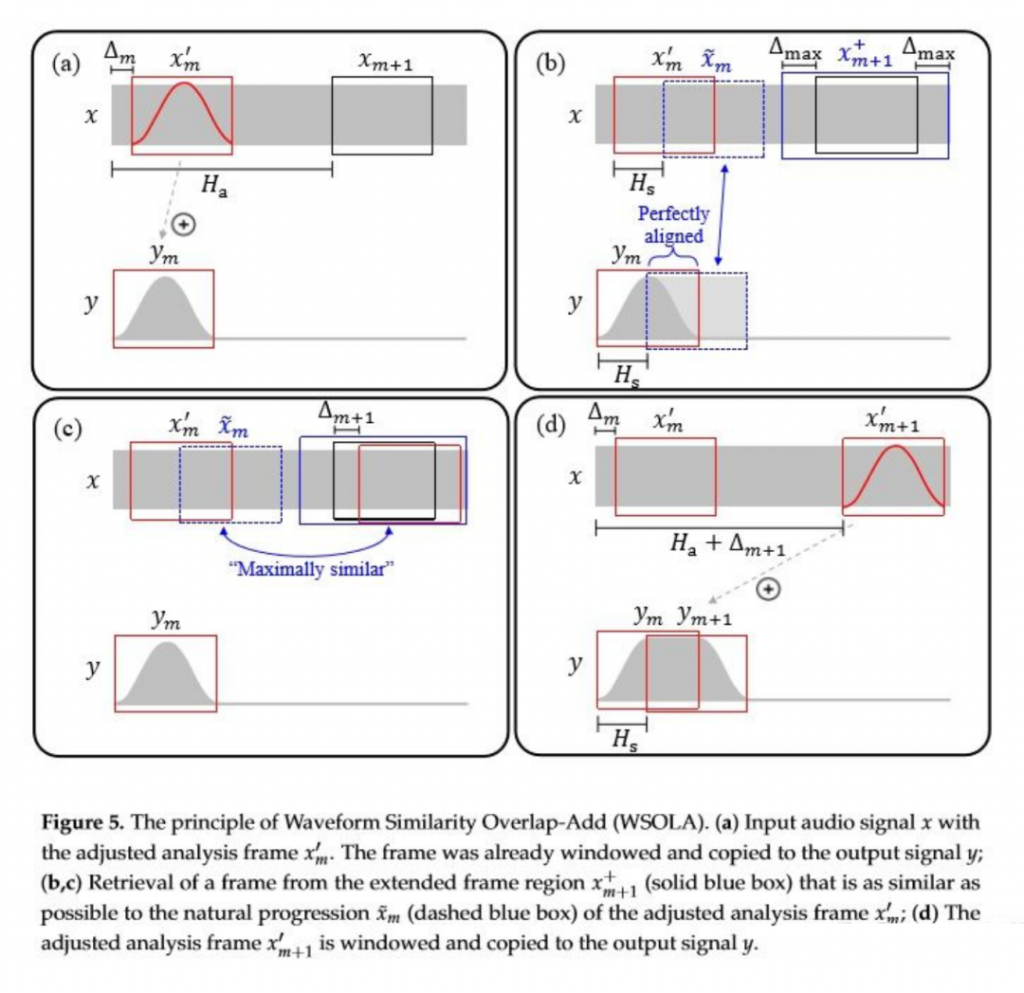
WSOLA 算法大致流程:

解码
从 packet_buffer_ 中获取数据,正常解码,解码数据存储到 decoded_buffer_ 中。
加速
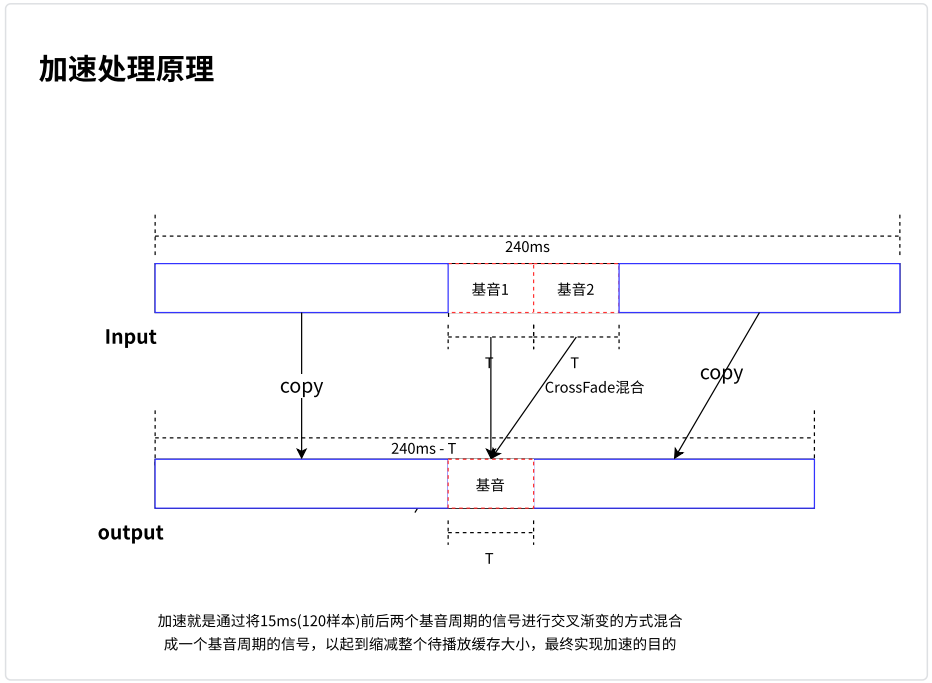
NetEQ 中,当 sync_buffer_ 和 packet_buffer_ 中的待播放数据总延时堆积过多,且前一帧和当前帧都正常时,需要通过加速播放操作,来降低抖动缓冲区待播放的数据量,以达到降低时延的目的,否则容易导致抖动缓冲区溢出,出现丢包。而加速是要求变速不变调的,WSOLA 算法通过寻找相似波形并对相似波形进行叠加来实现变速目的。
这里对 NetEQ 中的加速过程做简要描述:
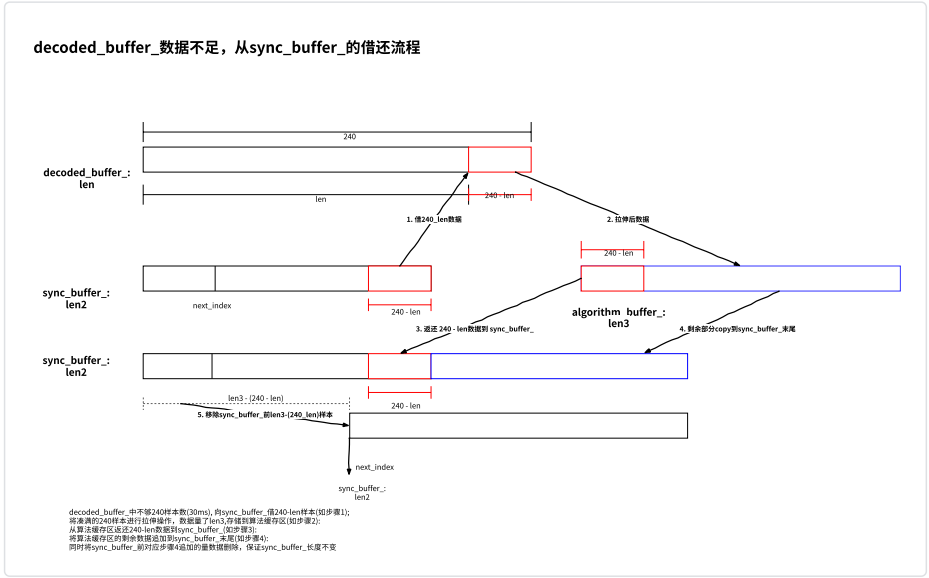
⾸先做加速要求最少需要 30ms 数据,数据一般来源于从 decoder_buffer_, 当 decoded_buffer_中得的数据不足 30ms,需要从 sync_buffer_中借一部分数据,凑满 30ms。
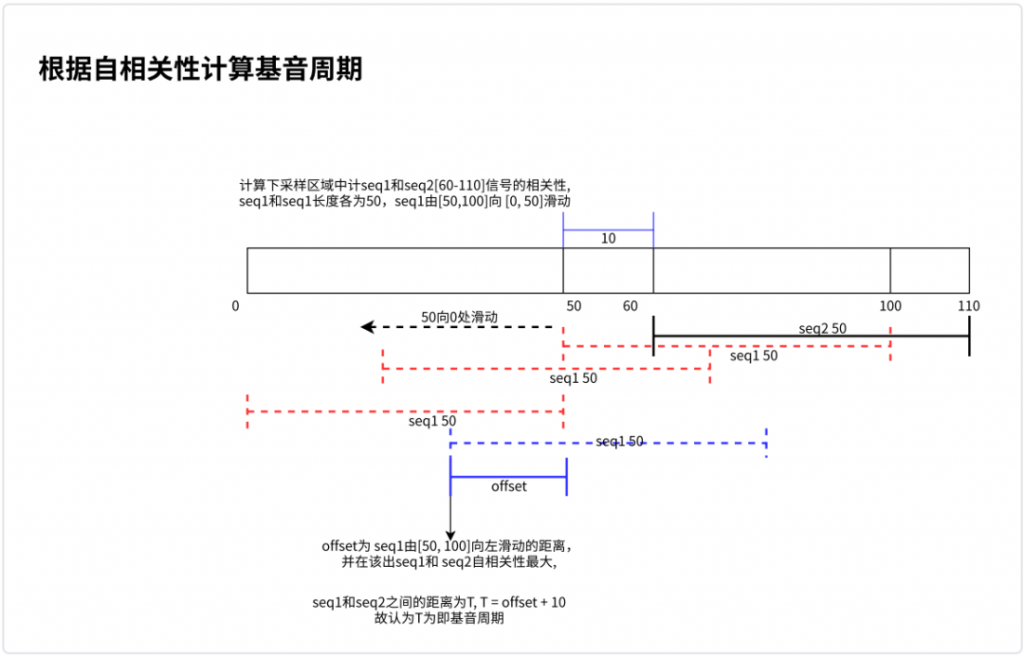
30ms 数据对应 240 个样本,将这 240 个样本下采样到 110 个样本;将下采样 110 个样本分成两部分 seq1 和seq2,seq2 为固定末尾 50 个样本,即[60,110]; seq1 也为 50 个样本,滑动范围[0,100],计算 seq1 和 seq2 的自相关性。
根据计算出来的自相关性结果,以抛物线拟合来找到自相关性峰值和位置,极大值出现的位置,即为上图中的 offset,即 seq1 窗口向左滑动的距离,所以基音周期 T = offset + 10。
在要加速的 30ms 样本中,取 15ms 和 15ms – T 这两个基音周期信号,分别记为 XY 计算这两个基音周期信号的匹配度。
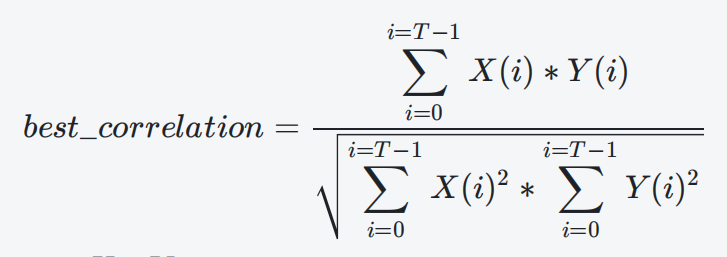
当 best_correlation 大于 0.9 时,则执行将两个基音周期信号合并为⼀个基音周期信号,起到加速作用
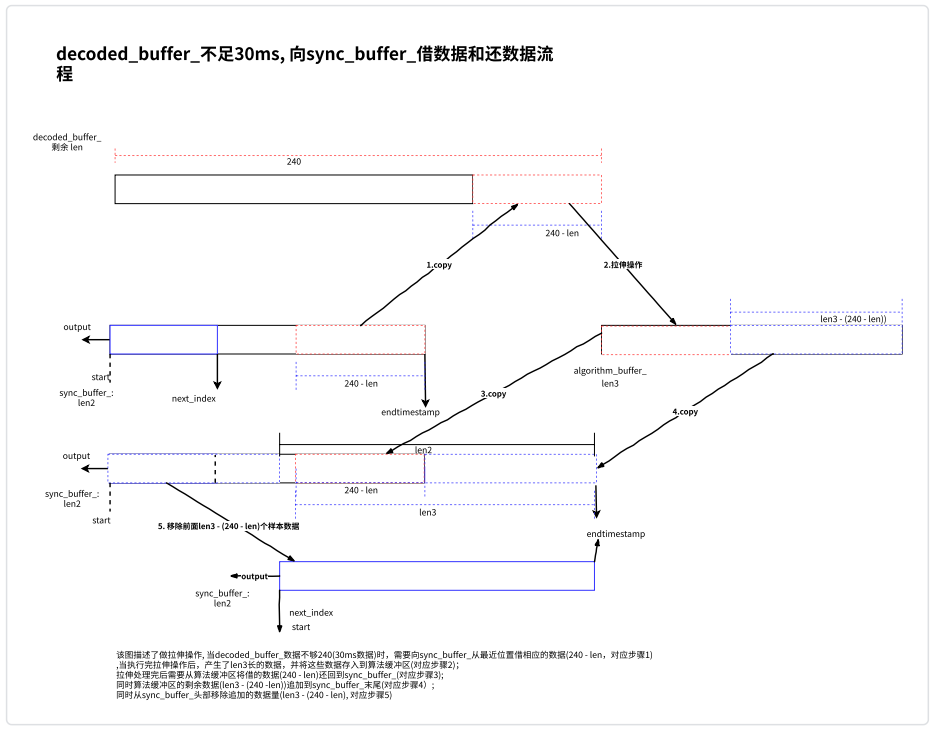
加速完的数据,如下图的 output 将存储到 algorithm_buffer_中,要是之前因为 decoded_buffer_中的数据量不够,从 sync_buffer_中借了部分数据,则需要从 algorithm_buffer_中将借的数据 copu 回 sync_buffer_对应的位置(目的是保证音频的平滑过渡),同时将 algorithm_buffer_中剩下的数据 copy 到 sync_buffer_末尾,如下图所示:
减速
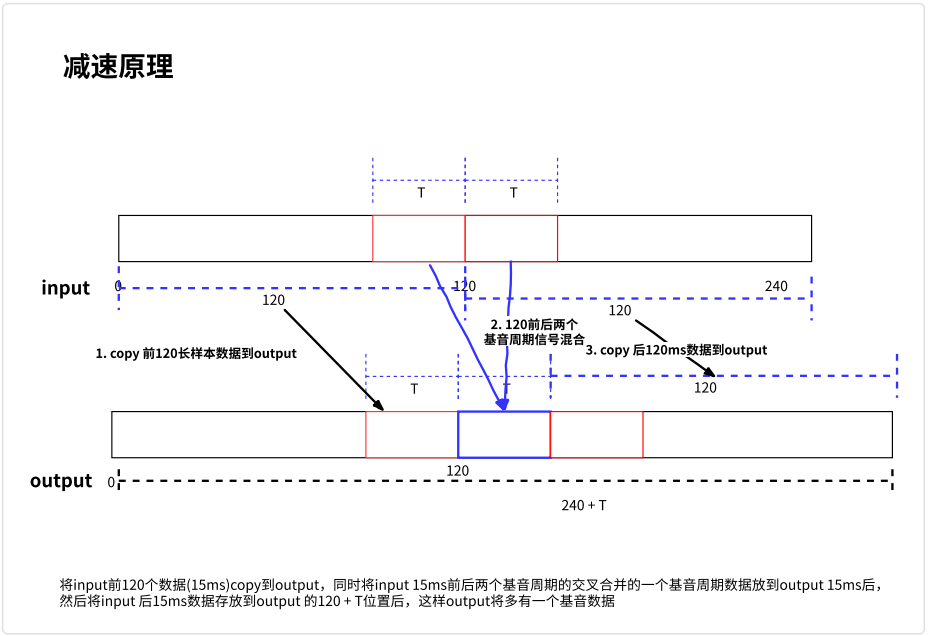
当 NetEQ 抖动缓冲中待播放的数据延时水平小于目标延时下限时,说明待播放的数据量小,为了达到播放端的最佳音质体验,需要将现有数据拉伸,适当增加播放数据量;这和加速是相反的操作,底层技术相同。同样下面对其做简要分析:
前 4 步和加速基本上是一样的,这里不再赘述
最后一步,是将 15ms – T 和 15ms 两个基音周期交叉渐变合并的混合基音插入到 15ms 后一个周期前。达到增加一个基音周期数据的目的,以此来增加播放数据量,同时需要从算法缓冲区中将借的数据返还给 sync_buffer_。
具体如下图所示:
丢包补偿
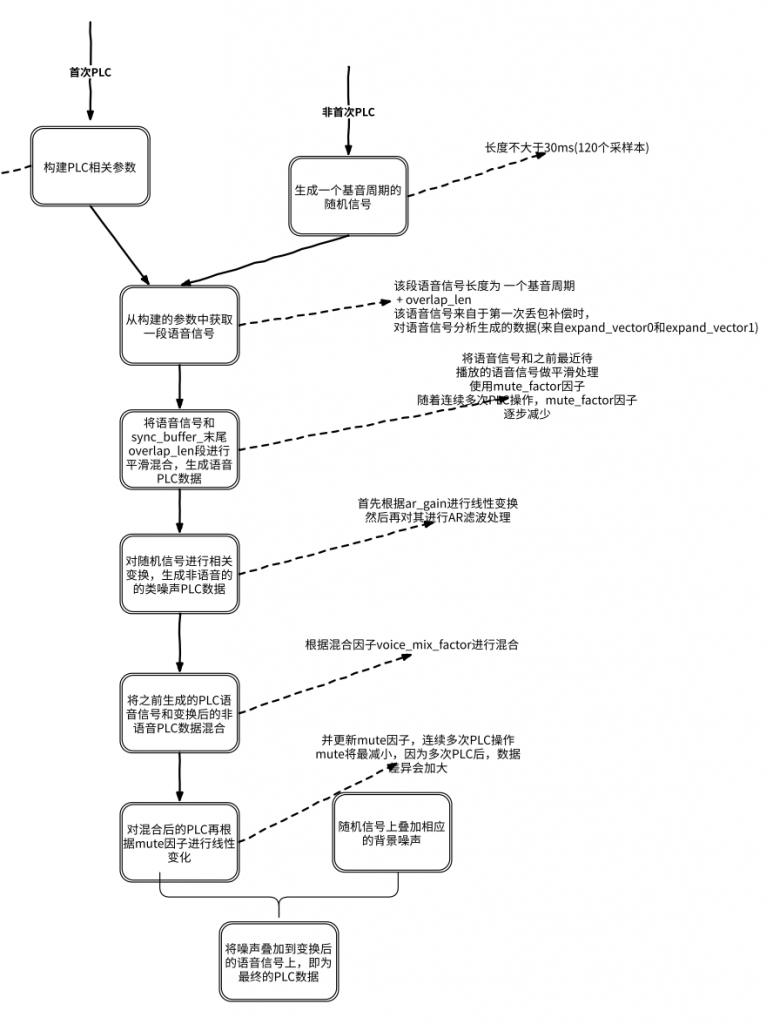
当前包丢失时,在 NetEQ 中会触发丢包补偿来预测丢失的包;丢包补偿有两种方式,一种是通过编解码器来预测重构丢失的包,另一种是通过 NetEQ 模块来预测重构丢失的包;对应分别是 kModeCodecPlc 和 kModeExpand。
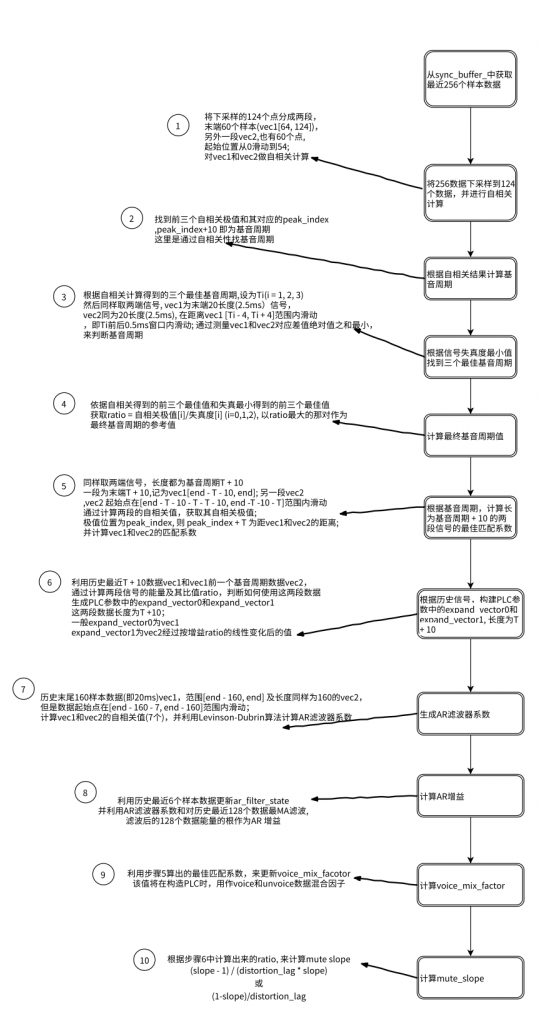
不论是何种模式,前提要求是 sync_buffer_ 中待播放的音频数据量小于当前请求要播放的数据量,才能执行该操作;丢包补偿通过最近的历史数据,来重构 PLC 相关参数,然后通过历史数据和 PLC 相关参数进行线性预测,恢复丢失的包,最后再叠加一定的噪声。
当连续多次 PLC 操作时,失真将会加大,所以多次操作后,将会降低 PLC 语音能量值。
下图是 NetEQ expand 操作的核心步骤。
PLC 操作中,首要任务是计算基音周期,这里使用了自相关计算和信号失真计算两种方式来计算基音周期,可通过下图简要说明。
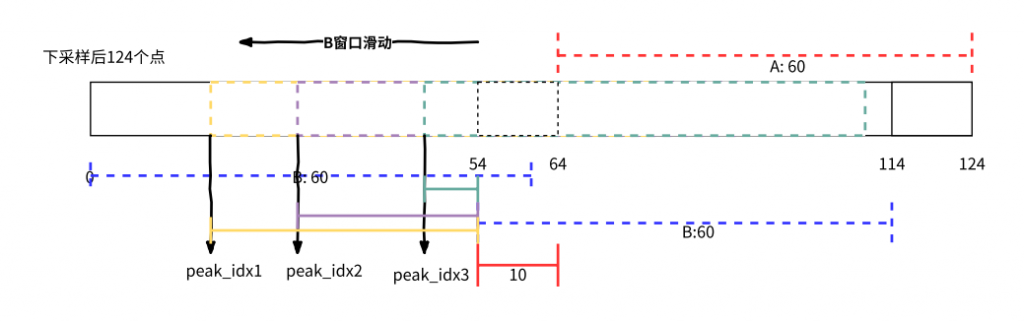
A 为末端 60 个样本信号
B 为滑动窗口,窗口包含 60 个样本信号,窗口起始位置滑动范围[0, 54]
通过计算 A 和 B 的自相关系数,得到 54 个自相关结果,对这 54 个自相关结果使用抛物线拟合找到三个最大值的位置 peak1_idx1、peak_idx2、peak_idx3 为三个自相关系数最大的值的位置
认为基音是周期信号,极值出现的位置为周期上
故基音周期 T
T1 = peak_idx3 + 10
T2 = peak_idx2 + 10
T3 = peak_idx1 + 10
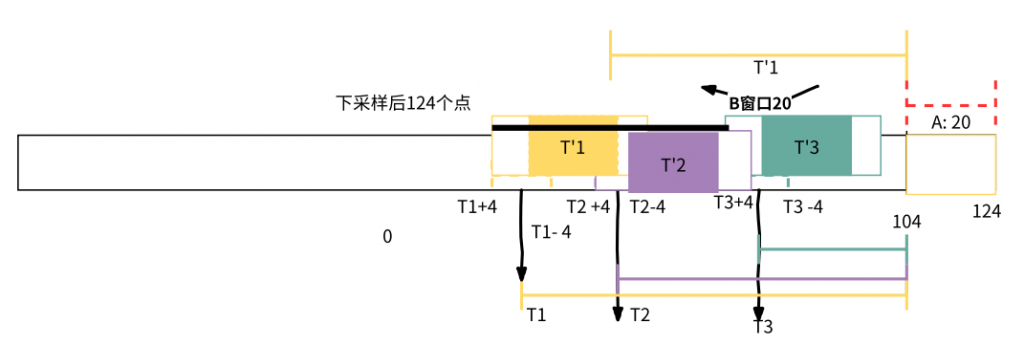
根据上面通过自相关及抛物线拟合找到的三个极值,得到了三个基音周期
取末端 20 个信号作为 A,滑动窗口 B 也是 20 个样本(2.5ms),B 在距 A 一个基音周期前后 4 个样本范围内(0.5ms)滑动
故有三个窗口滑动范围,计算三个范围内的窗口 A 和窗口 B 的失真度
取最小失真度三个极值,这三个极值作为通过失真最小计算的基音周期 T’
1, T’2, T’3
最小失真的衡量是以 A 和 B 对应元素差值绝对值之和最小为依据的
在得到基于自相关计算出来的三个基⾳周期 T1,T2,T3 和基于失真度最小得到的三个基⾳周期 T’1,T’2,T’3
通过比较这三对的 ratio = 自相值/失真度,当 ratio 最大时,则认为这对基音周期最佳
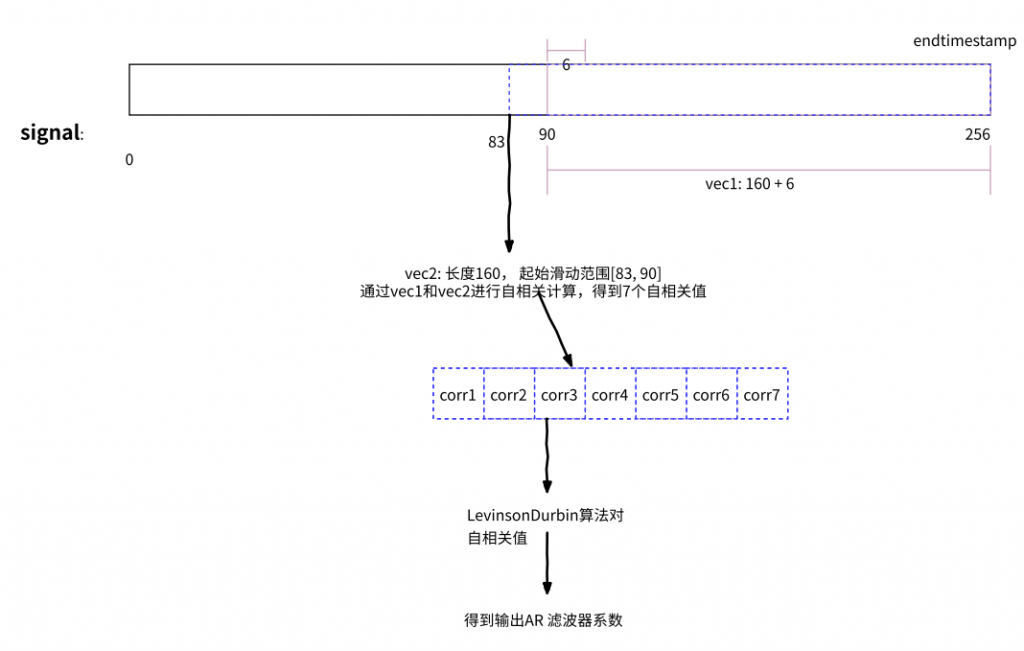
PLC 操作中,expand_vector0 和 expand_vector1 的计算细节如下图:
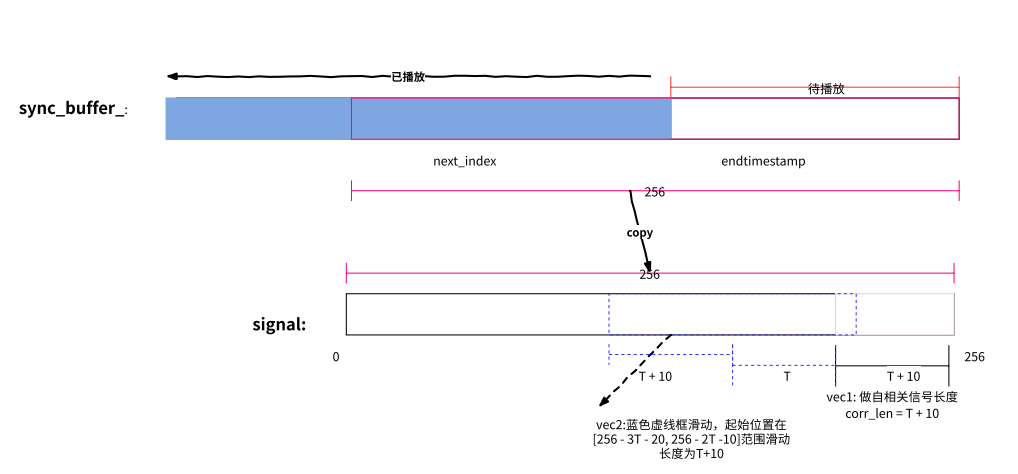
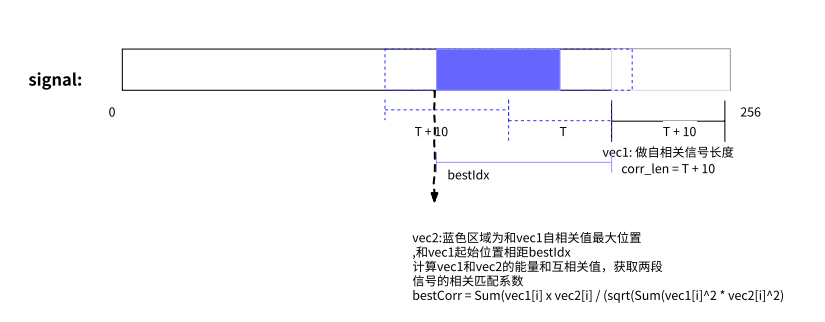
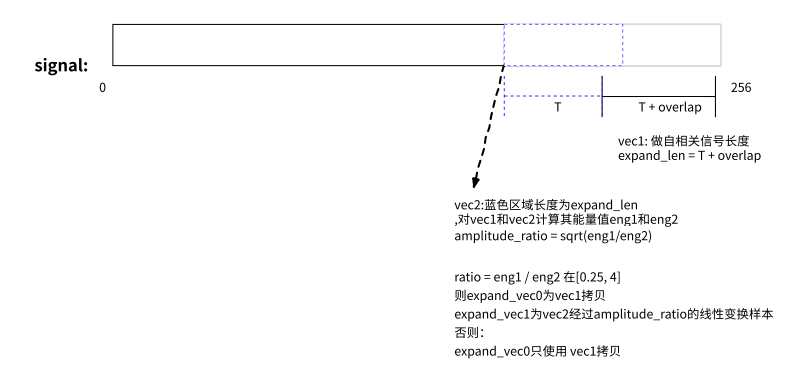
构造 AR 滤波器参数,通过获取一组(7 个)自相关值,对这组自相关值通过 LevinsonDurbin 算法计算,预测出 AR 滤波器参数。
AR 滤波器是线性预测器,通过历史数据来预测当前数据;在构建 PLC 包时,通过对历史数据进行 AR 滤波,来预测丢失的包信息。
下图是对这个过程的简要说明:
AR 滤波器公式如下所示:
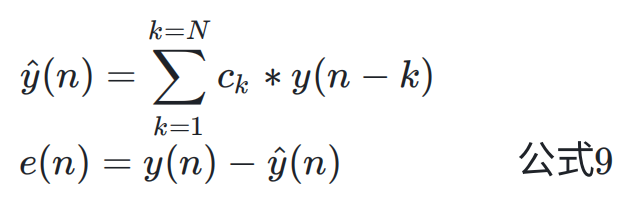
这里 k = 7;e(n)为预测值和实际值的误差;AR 滤波就是通过使用最近的历史数据来预测当前时刻数据;LevinsonDurbin 算法通过自相性值的计算来预测 ck,使得 e(n) 最小。
自相关性越大,说明 e(n) 越小;
LevinsonbDurbin 算法通过使用自相关性值来预测 AR 滤波器参数,可以理解为使⽤ e(n)来预测。
融合
融合操作一般是上一帧丢失了,但当前帧正常;
上一帧是通过预测生成的 PLC 包,和当前帧需要做平滑处理,防止两种衔接出现明显变化;
融合就是完成该功能,融合的组要过程有:
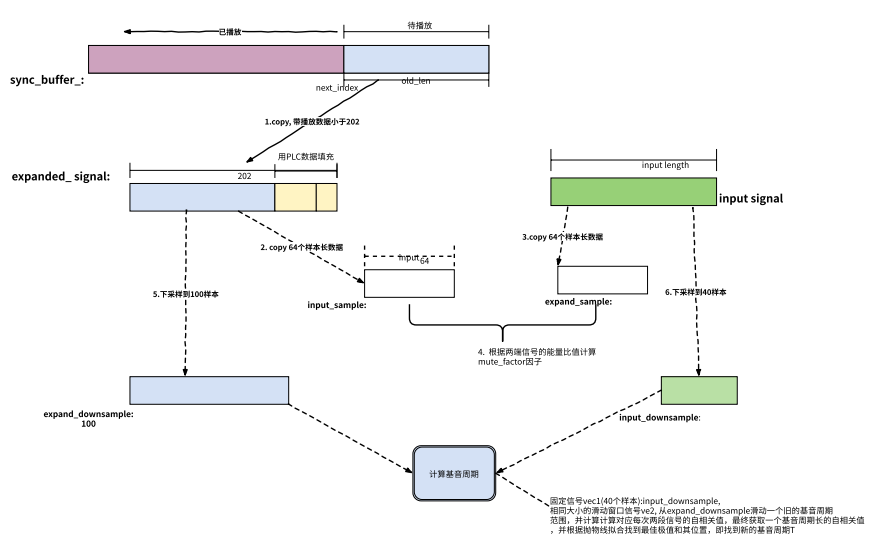
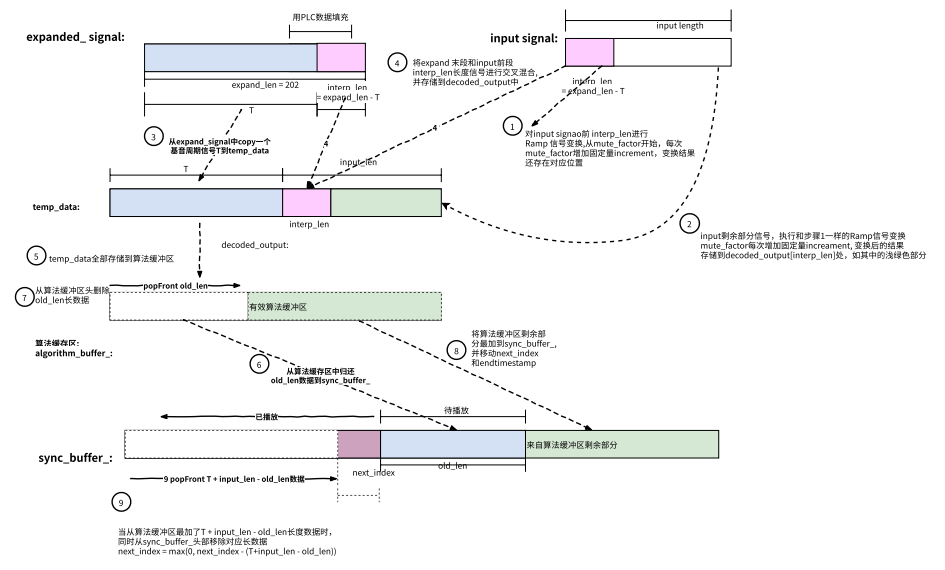
需要 202 个扩展样本信号,主要是向 sync_buffer_ 未播放的信号借用 sync_buffer_ 未播放的信号不足 202,通过生成足够 PLC 数据来凑满
通过扩展样本信号和输入信号,计算期它们的自相关性值,及通过抛物线拟合来获取基音周期
对 input 数据进行 Ramp 信号变换
对扩展信号和 input 信号部分段进行混合
从缓存算法取归还借用的信号数据到 sync_buffer_
将算法缓冲区剩余的平滑处理的信号追加到 sync_buffer_
下图对 NetEQ 中融合过程的简要说明:
normal
当前帧可以正常播放,也就是可以直接将这段信号送⼊到 sync_buffer_ 中, 但是因为上一帧可能是 expand 等,需要进行相关的平滑操作。
主要步骤如下:
将输入信号拷贝到算法缓冲区生成一段 PLC 数据包
根据背景噪声和输入语音信号的能量比值,计算 mute_factor
根据 mute_factor 对算法缓冲区数据按照能量从弱到强的趋势修正
将 expand 和算法缓冲区的头 1ms 音频数据进行平滑混合,结果存在算法缓冲区;
相关混合平滑公式如下:
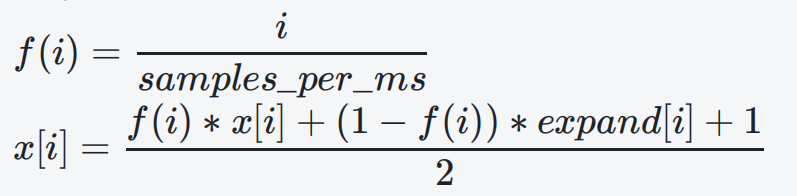
将最终的算法缓冲区数据最加到 sync_buffer_ 后
下图对 normal 的操作流程做补充说明:
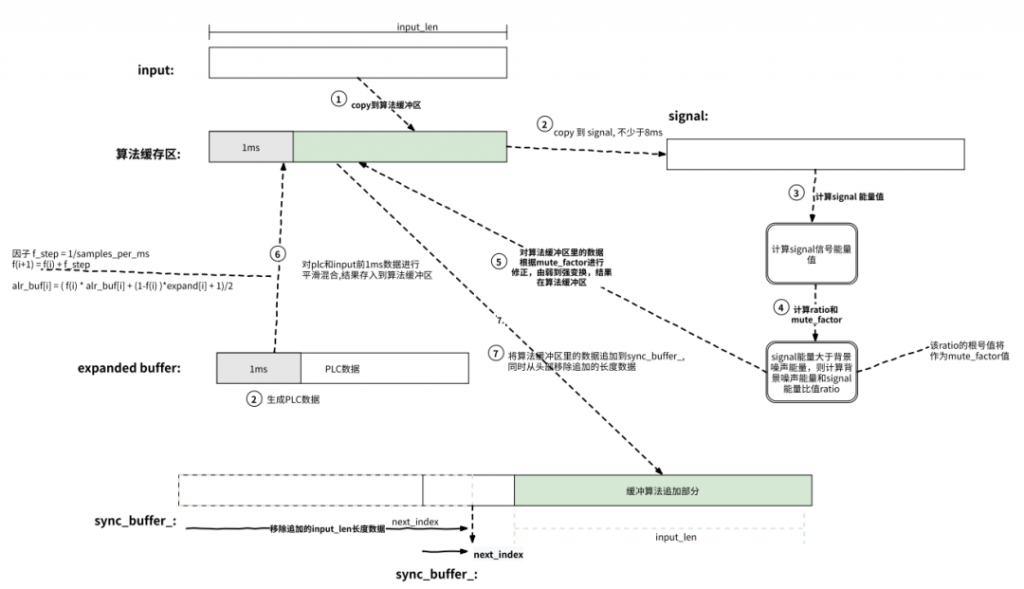
NetEQ 相关 buffer
NetEQ 为了消除抖动、解码音频数据、对解码数据进行 DSP 处理(加减速、PLC、融合、平滑数据),以及平滑播放等,使用了多个缓存 buffer,下面是对这些 buffer 的简要说明:
packet_buffer_: 用来接收网络中收到的音频包数据,也可称为抖动缓存,会定时删除当前时间 5 秒前的包,同时最多缓存 200 个包,即 4 秒(这⾥以每个包 20ms 计算)。
decoded_buffer_: 当播放线程每次获取音频数据来播放时,会根据目标延时和抖动缓存延时来判断是否需要从 packet_buffer_中获取音频数据进行解码,解码后的数据存放到 decoded_buffer_中。最多可缓存 120ms 数据。
algorithm_buffer_: decoded_buffer_中的数据经过 DSP 处理后,将存放到该缓存,一般每处理一次会清空一次。
sync_buffer_: 一般是从算法缓存拷贝过来的数据,是待播放的数据;sync_buffer_中有两个变量,一个是 next_index,表示当前播放的位置,next_index 前的数据表示已经播放,后面的数据表示待播放;另一个是 endtimestamp, 表示 sync_buffer_中最后一个待播放的数据,也就是最近的音频数据量。
该 buffer 可最多缓存 180ms 数据,是一个循环缓存;播放线程每次会从 sync_buffer_中取 10ms 数据进行播放。
关于何时从 packet_buffer_中取数据解码说明:
一般情况下每次从 packet_buffer_中取 10ms 数据进行解码。
当要执行 expand 操作时,但 sync_buffer_中有 10ms 以上数据,不从 packet_buffer_中取数据解码。
当做加速操作时,若 sync_buffer_中有 30ms 以上数据,不从 packet_buffer_中取数据;或若 sync_buffer_中有 10ms 以上待播放数据,同时上次解码了 30ms 数据,则不从 packet_buffer_中获取。
当加速操作,若 sync_buffer_待播放数据小于 20ms,同时上次解码的数据小于 30ms,从 packet_buffer_中获取 20ms 数据待解码。
当要做减速操作时,若 sync_buffer_中待播放的数据大于 30ms;或待播放的数据小于 10ms,但上一次解码的数据多余 30ms, 则不从 packet_buffer_中获取数据。
当要做减速操作,sycn_buffer_中待播放的数据量小于 20ms, 且上次解码的数据量少于 30ms,获取 20ms 数据进行解码。
NetEQ 能很好地跟踪网络抖动,同时在消除抖动时保证延时尽量小,对音频体验提升明显;结合上一篇关于弱网对抗的一些技术,可明显提升音频在弱网环境下的体验。
在社交产品花样繁多、玩法创新的当下,融云 IM 即时通讯不仅拥有强大的历史积累优势,同时在新社交形态频出的当下依然引流行业,永葆创新力和生命力。点击下方链接⬇️,快来体验吧~