
超分算法在 WebRTC 高清视频传输弱网优化中的应用
随着 5G 的发展应用,人们对音视频通信的品质要求在不断提高。习惯了高清视觉享受的用户,显然无法接受退回“马赛克时代”。
然而,在全球互联网通信云服务中,面对网络和终端的丰富多样和复杂多变,又难免遇到用户带宽不足的情况。使用技术手段来提高图像和视频分辨率,让用户在较低带宽的情况下依然获得较高清晰度的图像和视频就非常重要了。
本文分享使用图像超分辨率技术在有限带宽下实现 WebRTC 高清视频传输的优化方案。
视频编码中 影响视频清晰度的主要因素
理论上,对于同一种编码器而言,在分辨率不变的前提下,码率越大,视频质量越高。但是从视觉来看,在特定编码器和分辨率的情况下,码率存在一个最优值。
通常,视频通话/会议采用的视频压缩方案为 H264 或者 VP8。在 H264 编码中,720P 和 1080P 的视频推荐码率为分别为 3500Kbps 和 8500Kbps。
在移动设备中,H264 编码器推荐的码率如下表。
| _ | 1280 x 720 | 1920 x 1080 |
| 极低码率 | 500 Kbps | 1 Mbps |
| 低码率 | 1 Mbps | 2 Mbps |
| 中等码率 | 2 Mbps | 4 Mbps |
| 高码率 | 4 Mbps | 8 Mbps |
| 极高码率 | 8Mbps | 16 Mbps |
(移动端不同分辨率的推荐码率)
由上表可知,在 WebRTC 技术方案框架下进行视频通话时,采用 H264 编码器对 1080P 高清视频进行压缩,视频若设定为中等码率则需要 4Mbps。
对于带宽不足的部分终端用户,若仍然播放 1080P 的视频会存在卡顿的情况。则可以在 WebRTC 的技术框架下,采用联播(simulcast)或者 SVC 的方式,对不同的终端用户根据各自的特点传输不同分辨率或者不同帧率的码流。
简单来说,若用户的网络环境不适合传输 1080P 的视频,则给用户发送 720P 的视频,所需码率为 1080P 的一半,可以最大限度保障有限带宽下的视频传输流畅性。
高清已成趋势,在不改变编码器即 H264 或 VP8 的情况下,如何依然在终端上获得高清视频成为学术界和产业界需要共同研究和解决的课题。
图像超分辨率 技术在 WebRTC 中的应用
图像超分辨率技术(Super Resolution,SR)是计算机视觉中提高图像和视频分辨率的重要技术,可以将一幅低分辨率图像重建出高分辨率图像。
通俗地说,就是当我们放大一张尺寸较小的图像时,会出现模糊的现象,超分辨率重建就是将原图中一个像素对应的内容在放大之后的图中用更多的像素来表示,让图像尽可能地清晰。
随着深度学习的发展,目前图像超分辨率技术已经从传统的计算机视觉分析方法全面转向基于 CNN 和 Transformer 的方案。
将图像超分辨率技术应用于 WebRTC 的通常实现方式为:发送低分辨率的视频,在每一个终端显示的时候,采用超分辨率技术对图像进行放大。由于发送的视频为低分辨率的图像,可以在较低的传输视频数据量下获得较高的清晰度。
在 WebRTC 中,图像超分辨率算法需要同时满足实时超分和清晰效果的双重要求。通过对业界主流基于深度学习的超分算法进行广泛调研和实验,我们发现基于 ESPCN 进行优化可以满足要求。
ESPCN 由 2016 年发表在 CVPR 上的论文“Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network”提出,实验结果如图所示,达到了速度和精度的平衡。
篇幅所限,不在此展开介绍该模型的具体结构,感兴趣的同学可以关注微信公众号“融云全球互联网通信云”回复【超分】到后台获取论文。
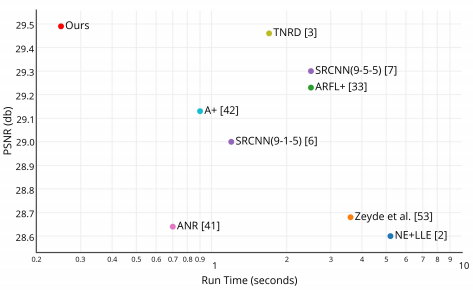
ESPCN 模型实验
在此次实验中,我们用 Pytorch 进行 ESPCN 模型的搭建、训练和推理。训练的数据一般可以采用常见的图像数据库,比如 PASCAL VOC、COCO 等,当然也可以根据行业特点采集相应数据集,让模型推理更有针对性。
为了增大数据库,我们在训练时会采用一些数据库扩容操作,最有效的方法之一是图像随机裁剪。该方法不仅能够对数据库进行扩容,而且可以弱化数据噪声与提升模型稳定性。
在 WebRTC 视频传输中,在编码端对图像进行 1/2 下采样。比如,传输 1080P 视频,在编码端视频的下采样为 960×540。
根据本文前述分析及部分实验效果表明,传输 960×540 分辨率的视频相较传输 1080P 的视频,数据量可以减少一半以上。
在实际应用中,当终端用户由于带宽限制无法直接传输 1080P 的视频时,可以传输 960×540 的视频,再采用 ESPCN 模型对 960×540 的视频进行超分重建获得原始 1920×1080 的视频,从而满足用户对高清视频的要求。
终端部署 ESPCN 模型优化
一般而言,深度学习模型训练完成后,需要模型对不同终端进行针对性地部署。
首先,我们通过模型量化缩小模型大小,减少对终端存储的占用,提升计算速度,加速深度学习推理的优化。
在这方面,Pytorch 框架提供了相应的接口,可以对模型进行各种量化,我们采用的是 int8 量化。
通过 int8 量化,模型中的部分数据从 float 变成 int 型,采用 libtorch 集成到 WebRTC 中,训练好的模型会转换成 libtorch 可以读取的 pt 格式。
结果显示,未量化之前 ESPCN 模型大小为 95KB,量化之后为 27KB。
其次,针对不同型号手机的推理优化,从 256*256 上采样到 512*152,该模型在华为 P10 等中高端手机上可以达到 30ms 的推理速度,在 Asus Fonepad 8、Samsung Galaxy M31 等终端上目前实时表现尚不理想。我们还将采用剪枝和各种量化手段持续优化模型,满足各类手机的要求。

ESPCN 模型实验结果
模型读取部分关键代码如下所示,其中 espcn.pt 为未量化之前的模型。
// Deserialize the ScriptModule from a file using torch::jit::load().
auto device = torch::kCUDA;
std::string str = "espcn.pt";
try
{
module = torch::jit::load(str, device);
}
catch (const c10::Error& e)
{
std::cerr << "error loading the model\n" << e.what();
}
pmodule = &module;模型的推理如下代码所示,output 即为模型推理的输出。因为输出的数据为 0 到 1,需要对输出数据进行限定和转换。
需要注意的是,ESPCN 模型默认是针对 Y 通道的超分,对 UV 数据而言,直接进行双三次插值(bicubic),即完成了 YUV 三个通道的超分。
std::vector<torch::jit::IValue> inputs;
inputs.push_back((img_tensor1.cuda()));
at::Tensor output = pmodule->forward(inputs).toTensor();
output = output.mul(255).clamp(0, 255).to(torch::kU8);量化后的 ESPCN 模型效果

将原始图像采用双三次插值(bicubic)
放大成目标尺寸

通过 ESPCN 模型超分重建


从视觉效果来看,ESPCN 模型的效果要远好于 bicubic 插值的方法。
本文主要介绍了基于图像超分辨率技术进行 WebRTC 传输优化的方案,涉及模型选择、训练、量化等方面。
视频传输优化方案众多,图像超分辨率技术仅是其中之一。在实时音视频交互成为通信基本诉求的当下,融云会积极结合相关理论和成熟算法,研发新技术,对视频压缩和传输进行优化,满足遍布全球、需求各异的各类用户需求。